1 INTRODUÇÃO
O aquecimento
global vem exigindo, dos mais diversos segmentos econômicos, uma rápida adaptação ao conceito de
sustentabilidade. Sendo tema de discussão não apenas da comunidade científica,
mas dos governantes e da opinião pública [1].
O
desenvolvimento da sociedade moderna anda de mãos dadas com a demanda de
energia e a capacidade de produzi-la [2]. E o setor energético mundial foi responsável por 33,3
bilhões de toneladas de emissão de CO2 em 2019 [3], o que torna irremediável a transição
para uma matriz energética sustentável. Os dados da Agência Internacional de
Energia (IEA) [3],
demonstram ainda que, apesar de ter ocorrido um corte nas emissões de CO2 pelos
países desenvolvidos, as nações emergentes emitiram mais gases que em relação a
2018.
O Brasil
apresenta situação privilegiada em termos de potencial de geração de energia
elétrica a partir de fontes renováveis, isso deve-se ao fato do amplo uso das
hidrelétricas para geração da nossa energia. Juntas as fontes sustentáveis de
energia representam em 2021 mais de 85% da capacidade instalada no Brasil [4].
Embora o
Brasil tenha uma grande matriz hidráulica para geração de energia, quase todo
potencial está sendo aproveitado. Existe, também, uma dificuldade na construção
de novas hidrelétricas por restrições ambientais e sociais [5]. E por isso, as novas hidrelétricas,
em sua predominância, estão sendo construídas com caráter de fio d’água [6], minimizando a capacidade de
regularização das vazões e gerando um perfil de intermitência, diretamente
associado à pluviosidade na bacia hidrográfica [7].
Essa
característica nos deixa “reféns” da chuva o que pode comprometer a
regularidade da produção hidroelétrica, implicando na necessidade de utilização
das termelétricas, geradoras de energia bem mais caras e poluentes [8].
A tecnologia
fotovoltaica, de característica sustentável, apresenta grande crescimento no
mundo. De acordo com o relatório da Renewables Global Status Report [9], as energias renováveis cresceram 200
GW em 2019, sendo a fonte solar fotovoltaica responsável por 57,5% (129W),
seguida pela fonte eólica com 30% de participação (60 GW) e a fonte
hidrelétrica 8% (18 GW).
Em relação à
capacidade instalada solar fotovoltaica, os principais países do mundo são
China, Japão e EUA, conforme ranking de 2019 da ABSOLAR. O Brasil aparece
apenas na 16ª posição.
No Brasil a
região Nordeste se caracteriza pela boa incidência de irradiação solar direta,
principal fator para a viabilidade desta tecnologia. Se apresentando como uma
excelente opção para a complementação da demanda das consolidadas
hidroelétricas, favorecendo o controle hídrico nos reservatórios nos períodos
de menor incidência de chuvas [10].
Até maio de 2021, o Nordeste conta com
a maior potência outorgada de usinas fotovoltaicas, conforme informações
disponíveis pela plataforma da ONS (Operador Nacional do Sistema) [11]. No Quadro 1, com informações
retiradas do Sistema de Informações de Geração da ANEEL (SIGA), fica
demonstrada a distribuição da Potência Outorgada no Brasil (kW) proveniente da
Radiação Solar [12].
Quadro
1: Distribuição da Potência Outorgada no
Brasil.
|
UPV
|
POTÊNCIA
|
%
|
|
Nordeste
|
2.409.659
|
71,41
|
|
Norte
|
14.492
|
0,43
|
|
Centro-oeste
|
5.971
|
0,18
|
|
Sudeste
|
931.732
|
27,61
|
|
Sul
|
12.688
|
0,38
|
|
TOTAIS
|
3.3743.544
|
100%
|
Fonte: ANEEL - SIGA (2021).
Contudo, por
depender de condições climáticas, tais como radiação solar, temperatura,
velocidade do vento [13, 14] entre outras variáveis, há de se considerar a necessidade de previsão
para estimar o potencial instalado e planejamento [15, 16]. Daí o surgimento de inúmeras técnicas
de predição que promovem uma maior previsibilidade ao operador do sistema
elétrico.
Entre estas
técnicas, se pode destacar a utilização de redes neurais artificiais.
Justamente por sua capacidade de “aprender” padrões através do treinamento.
Ainda mais quando os dados não possuem relação bem definida e/ou não lineares.
Sendo mais difícil a adoção dos métodos convencionais [17, 18].
Ainda, para a
caracterização do objeto do trabalho é importante descrever que séries
temporais são um conjunto de observações ordenadas no tempo que, aparentemente,
não seguem nenhuma lei ou tendência [18, 19]. No entanto, em diversos exemplos de séries temporais
estudados, como os relacionados a fenômenos naturais e dados climáticos, é possível
identificar características que se repetem após determinado período de tempo
(sazonalidade), mesmo que não sejam padrões lineares [18, 19].
Nesse contexto, esse estudo se propõe a utilizar um método
linear clássico ARIMA e outros dois de redes neurais artificiais, o MLP e LSTM,
para desenvolver uma metodologia na previsão de geração de energia, a partir
dos dados meteorológicos disponíveis para a região Nordeste brasileira. Para
isto, são usados os dados das Usinas do Conjunto Fotovoltaico BJL Solar
localizado em Bom Jesus da Lapa/BA.
A escolha do Conjunto BJL Solar se
deve por existir grande disponibilidade de dados temporais na plataforma da ONS
e, ainda, possuírem dados climáticos disponibilizados pelo INMET nesta
localidade. Assim, se pode extrair o máximo potencial das redes neurais
artificiais na predição, sem a necessidade de técnicas de interpolação para
estimar dados e condições climáticas. O Conjunto Fotovoltaico BJL Solar possui
dados de geração de energia desde ABR/2018.
Este trabalho está organizado em
quatro seções. A Seção 1 introduz o atual momento do Setor e a importância de
utilização de modelos de predição na área de energia solar; na Seção 2 são
apresentados os materiais e métodos que foram utilizados para o estudo em
questão. A Seção 3 descreve como foi realizado o estudo experimental e a Seção
4 apresenta os resultados. Na Seção % consta uma breve discussão onde é
proposto novas ideias para futuras melhorias.
2 MATERIAIS E MÉTODOS
A seguir são apresentados os conjuntos
de dados selecionados para o estudo, os procedimentos metodológicos empregados
na predição das séries temporais e as observações e análises obtidas do
experimento realizado.
2.1 COLETA
DE DADOS
Abaixo são descritos os procedimentos
e os critérios adotados para coleta dos dados.
ONS: Por meio do portal do Operador
Nacional do Sistema Elétrico (ONS) é possível obter os dados de geração de
energia horária do Conjunto Fotovoltaico BJL Solar [20], localizado em Bom Jesus da Lapa, no
Estado da Bahia.
Apesar de instalada em meados de
ABR/2018, o atual potencial de geração de energia do Conjunto Fotovoltaico BJL
Solar é atingido a partir de NOV/2018. Assim, foi utilizada a Geração de
Energia (MWmed) no modelo de predição.
INMET: Através do portal do Instituto
Nacional de Meteorologia (INMET) é possível obter os dados históricos anuais de
diversas estações meteorológicas espalhadas pelo Brasil [12]. O histórico disponível é entre os
anos de 2000 e março/2021 onde é disponibilizado as medições horárias. Assim
foi coletado os dados da Estação Meteorológica de Bom Jesus da Lapa a partir de
ABR/2018 em acordo com os dados de geração de energia disponibilizados pela ONS
do Conjunto Fotovoltaico BJL Solar.
Neste trabalho optou-se por utilizar
os 17 atributos disponíveis para potencializar a predição.
O DOI é um padrão de letras e números
que funciona como identificador do texto. Essa informação é inserida na nota de
rodapé localizada no final da folha. Sendo essa informação acrescida pelo corpo
editorial após aceitação do artigo.
SOLCAST: Desenvolvido em 2015, é uma das
plataformas de referência no mundo quando se trata de dados de irradiação
solar. Desenvolvida por uma equipe de cientistas de dados e engenheiros
localizados na cidade de Palo Alto na Califórnia, suas ferramentas de captura
de dados contam com uma frota global de satélites meteorológicos
geoestacionários. Nela é possível obter dados em tempo real e/ou o histórico de
dados horários da irradiância solar em praticamente qualquer local do mundo [21].
Os 18 atributos disponíveis foram
utilizados no estudo de predição.
2.2
METODOLOGIA
Nesta subseção está descrito o método,
a forma e o tipo de análise realizada. Constará os principais passos de
pré-processamento e os conceitos fundamentais adotados na estimativa de
produção de geração de energia fotovoltaica adotados nos modelos utilizados que
foram o linear ARIMA e os de redes neurais MLP e LSTM.
2.2.1 Pré-processamento de Dados
A partir da
coleta de dados, conforme descrito na subseção 2.1, foi reunido o conjunto de
atributos identificados como relevantes nesse trabalho em uma única tabela. Que
após as fases de pré-processamento descritas a seguir objetivam a montagem do
conjunto de treino e testes a ser utilizado no modelo clássico e nos de machine
learning.
Inicialmente é
observado que por se tratar de medições horárias, diversos dados não constavam.
Após análise, verificou-se que tratam de momentos em que não ocorreram leitura,
como pode ser facilmente exemplificado pelo atributo precipitação total (mm)
que consta da tabela do INMET. Assim, esses dados foram preenchidos com o valor
zero. Dessa forma, cada atributo foi analisado e preenchido os valores
faltantes de acordo com as características necessárias para manter a
integridade da base e a efetividade no resultado final do estudo.
Após a
aglutinação dos dados do INMET, ONS e SOLCAST a base de trabalho resulta em
colunas temporais (horárias) e com 35 atributos. Como critério, esse estudo
adota o maior número de características dessas bases com o objetivo de
maximizar o resultado dos modelos de predição.
Outro aspecto
para a organização dos dados foi a normalização e para isso foi adotada a
função MinMaxScaler da biblioteca scikit-learn. Assim os atributos são transformados
em valores entre 0 e 1, preservando a distribuição original de cada coluna de
forma independente. A função MinMaxScaler segue a equação (1):
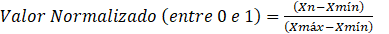 (1)
(1)
Onde:
Xn: valor do atributo da série temporal original a ser
normalizado;
Xmín: valor mínimo da série temporal associada à
variável (ao atributo) em questão; e,
Xmáx: valor máximo da série temporal associada à
variável (ao atributo) em questão.
2.2.2 Modelos ARIMA
Importante
classificar, inicialmente, que uma série temporal é um conjunto de observações
ordenadas no tempo (não necessariamente igualmente espaçadas), e que apresentam
dependência serial (isto é, dependência entre instantes de tempo) [22].
O modelo ARIMA
(autoregressive integrated moving average, na sigla em inglês) é uma
generalização do modelo ARMA (modelo autorregressivo de médias móveis) no qual é adicionado o conceito de
integração. Ambos são modelos para a análise de séries temporais e predição. A
metodologia do ARIMA consiste em ajustar modelos autorregressivos integrados de
médias móveis a um determinado conjunto de dados [18, 23].
O Seasonal
ARIMA (SARIMA ou SARIMAX), é uma extensão do modelo ARIMA que permite
identificar e considerar a sazonalidade [18, 23]. Além disso, o modelo SARIMA também trabalha bem com
dados exógenos.
O ARIMA (p, d,
q) vem seguido de três aspectos chaves que são: a ordem de auto regressão (p);
o grau de diferenciação (d); e, a componente de médias móveis (q). Sendo
necessário fornecer estes valores na busca de um bom modelo. Para a verificação
dos modelos gerados a partir da série temporal em estudo, visando o ajuste
ideal dos parâmetros para fornecer a melhor previsão pelo ARIMA (p, d, q) é
usado a função ‘autoarima’ [18].
No modelo SARIMA [(p, d, q)(P, D, Q)m]
são adicionados mais 4 parâmetros: o P (maiúsculo, para a ordem auto regressiva
sazonal); o D (maiúsculo, para a ordem de diferenciação sazonal); o Q
(maiúsculo, para a ordem de médias móveis sazonal); e, o m (número de passos
para um único período sazonal) [18, 23].
2.2.3 Modelos MLP
Modelo de rede
neural que se destacam pelas seguintes características dos perceptrons
multicamadas [17]:
·
O modelo de cada neurônio na rede
inclui uma função de ativação não linear
que é variável;
·
A rede contém uma ou mais camadas
que estão ocultas dos nós de entrada e saída; e,
·
A rede exibe alta conectividade,
cuja extensão é determinada pelos pesos sinápticos da rede.
No que diz
respeito ao seu funcionamento e arquitetura o algoritmo back-propagation
destaca as redes Multilayer (feedforward) Perceptron e, de forma geral,
possuem duas etapas [17]:
·
Forward: Onde o vetor de entrada é
aplicado à camada de sensoriamento e seus resultados propagados até a camada de
saída com os pesos fixos durante o processo; e,
·
Backwards: em que são feitos os
ajustes dos pesos.
2.2.4 Modelo LSTM
A Long
Short-Term Memory, ou LSTM, é um tipo de Rede Neural Recorrente.
Redes Neurais
Recorrentes, ou RNNs, são um tipo especial de rede neural projetada para
problemas de sequência. Dada uma rede MLP feedforward padrão, uma RNN
pode ser pensada como a adição de loops à arquitetura que permitem que as
informações persistam. Ou seja, no caso mais simples, a rede vê uma observação
por vez de uma sequência de dados e pode aprender quais observações que ela viu
anteriormente são relevantes para fazer uma previsão [23].
Contudo, o
principal desafio técnico enfrentado pelas RNNs é como treiná-las de forma
eficaz (devido aos problemas da dissipação do gradiente – vanishing – ou
da explosão dos gradientes – exploding – nas camadas iniciais). Assim,
surgem as LSTMs com um novo design e que é popularizado por evitar os problemas
que impedem o treinamento e dimensionamento que existem nas demais RNNs [23].
Assim a
arquitetura LSTM, também chamada de “redes de memória de longo-curto prazo”,
cumpre a promessa para a predição de sequências com a característica de
persistência. E, devido a essa capacidade de aprender correlações de longo
prazo em uma sequência, conforme descrito nos parágrafos anteriores, as redes
LSTM evitam a necessidade de uma janela de tempo pré-especificada e são capazes
de modelagem de sequências multivariadas complexas [23].
A LSTM possui
uma estrutura em cadeia que contém quatro camadas de interação e diferentes
blocos de memória. Essas estruturas são chamadas de células. O termo neurônio
como unidade computacional é tão arraigado ao descrever MLPs que,
frequentemente, também é usado para se referir à célula de memória LSTM.
Contudo, as células LSTM são compostas por pesos (weights) e portas (gates). De
forma geral a informação fica retida nas células (que possuem parâmetros de
peso em sua entrada e saída) e as manipulações de memória são realizadas nos
portões (gates) [23].
Logo, a base
para a memória das células está nos portões. Que também possuem funções ponderadas
e que governam o fluxo das informações. São três as portas nas células: Forget
Gate, Input Gate e Output Gate. Os portões são uma forma de proteger,
controlar e, opcionalmente, deixar passar informações pelas células [23].
Assim as LSTMs
possuem como principais características [23]:
·
Consegue resolver os problemas
técnicos de treinamento de uma RNN (vanishing e exploding);
·
Agregar memória para superar
problemas que possuem dependência temporal de longo prazo com dados de entrada
sequenciais; e,
·
Consegue processar dados
sequenciais de entrada e de saída gradualmente, permitindo variar os
comprimentos de entrada e de saída dos dados.
2.2.5 Métricas de Avaliação
Para avaliar o
desempenho de previsão dos 3 tipos de modelos usados, foram utilizadas medidas
que expressam o erro médio do modelo preditivo em relação ao modelo original.
Por se tratar de métricas que expressam “erros” quanto menor seu valor melhor o
modelo avaliado.
Assim, está
listado a seguir, as métricas utilizadas para a avaliação dos modelos
estudados.
Na equação
(1), a raiz do erro quadrático médio (RMSE, na sigla em inglês) é a medida que
calcula "a raiz quadrática média" dos erros entre valores reais de
geração de energia e as predições [27].
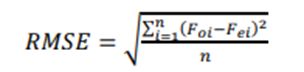 (2)
(2)
Na equação
(2), o erro médio absoluto (MAE, na sigla em inglês) é a diferença média
absoluta entre valores reais de geração de energia e os valores previstos. Essa
métrica varia de zero a infinito. Um valor menor indica um modelo de qualidade
superior [27].
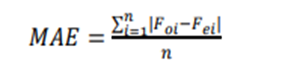 (3)
(3)
Nas equações (2) e (3) temos:
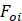 -
representa a produção de energia na hora i;
-
representa a produção de energia na hora i;
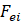 -
representa a produção de energia estimada pelos modelos (ARIMA ou de
aprendizado de máquina) na hora i; e,
-
representa a produção de energia estimada pelos modelos (ARIMA ou de
aprendizado de máquina) na hora i; e,
n - corresponde ao número de dados utilizados no estudo
preditivo (dados para o treinamento).
3 ESTUDO EXPERIMENTAL
Nesta seção
serão apresentadas as configurações dos modelos para o processo de busca dos
hiper parâmetros de cada arquitetura utilizada e as métricas de avaliação.
Foram empregados
os atributos, conforme coleta de dados descrita nas subseções anteriores, para
a previsão de energia fotovoltaica. Ao todo são 8.737 observações e 35
atributos sendo o conjunto de treino e teste divididos da seguinte forma 6.552
instâncias (75%) para treinamento e 2.185 instâncias (25%) para testes.
Para o estudo
foi usado um computador com processador 1.6 Intel® Dual Core™ i5, CPU 1.6Ghz
com 8.00GB RAM. Foi utilizada a linguagem Python 3.7.10 com o auxílio das
seguintes bibliotecas: Pandas, NumPy, TensorFlow, Pmdarima, Scikit-learn,
Keras, StatsModels, Matplotlib e Pydot.
3.1 Aplicação dos Modelos
A seguir, encontra-se
as configurações e hiper parâmetros adotados nos modelos estudados.
ARIMA/ SARIMA: Visando o ajuste ideal dos parâmetros
para fornecer a melhor previsão foi usado a função ‘autoarima’ que retornou à
configuração:
![Best model: ARIMA(0,0,0)(0,0,0)[24] intercept](http://revistas.poli.br/index.php/repa/article/download/1767/787/9873)
Adotando o
resultado obtido na função ‘autoarima’ tem-se o modelo SARIMA (p,d,q =
[0,0,0] e sazonal (P,D,Q [0,0,0]), com período sazonal m = 24. Assim, é
implementado o modelo SARIMA conforme a seguir:

As métricas de
avaliação obtidas para o SARIMA foram:

MLP: Neste modelo é utilizado uma rede
neural com duas camadas ocultas, função de ativação RELU, otimizador ADAM,
função de perda MSE (Mean Squared Error) e um neurônio na camada de
saída. Os hiper parâmetros utilizados foram: número de neurônios na camada
oculta: 32 e 64; número de épocas 150; e, batch_size 16.
Figura 1: Arquitetura utilizada na MLP
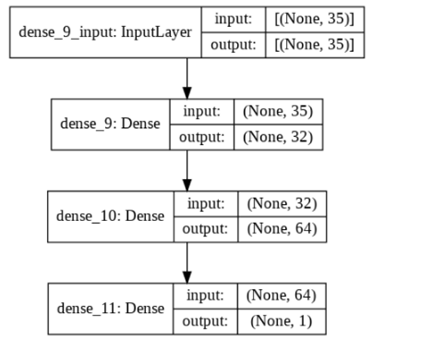
Fonte: O autor.
As métricas de
avaliação obtidas para a MLP foram:

LSTM: Para este modelo de rede neural foram
aplicadas duas camadas ocultas, função de ativação RELU, otimizador ADAM,
função de perda MSE (Mean Squared Error) e um neurônio na camada de
saída. Os hiper parâmetros utilizados foram: número de neurônios na LSTM: 64;
número de neurônios na camada oculta: 32; número de épocas 150; e, batch_size
16.
Figura
2: Arquitetura utilizada na LSTM

Fonte: O autor.
As métricas de
avaliação obtidas para o modelo LSTM foram:

MLP + GridSearch: Ainda, se utilizou o recurso GridSearchCV,
com um dicionário de parâmetros, com o objetivo de encontrar a melhor configuração
para o modelo MLP.
![# Use scikit-learn to grid search
activation = ['relu', 'tanh', 'sigmoid', 'linear'] # softmax, softplus, softsign
dropout_rate = [0.0, 0.4,0.7]
neurons = [1, 5, 10, 15, 20, 25, 30]
##############################################################
# grid search epochs, batch size
epochs = [50, 100, 150] # add 50, 100, 150 etc
batch_size = [16, 32] # add 5, 10, 20, 40, 60, 80, 100 etc
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, scoring='neg_root_mean_squared_error', cv=3)
grid_result = grid.fit(x_tentativa, y_tentativa)
# print best parameter after tuning
print(grid.best_params_)](http://revistas.poli.br/index.php/repa/article/download/1767/787/9880)
O melhor
modelo entre as combinações do dicionário de parâmetros foi:

As métricas de
avaliação obtidas para o modelo LSTM com GridSearch foram:

4 RESULTADOS
Nesta Seção é
demonstrado os valores obtidos por meio das métricas estatísticas de ajuste
priorizadas no estudo.
Por definição,
o RMSE eleva ao quadrado a diferença dos erros entre o conjunto de dados reais
e os de predição, antes de ter a média calculada. Assim, a presença de outliers
no conjunto de dados resulta em valores superiores quando comparados ao MAE. A Tabela
(1) mostra os resultados obtidos.
Tabela
1: Métricas com os
resultados obtidos.
|
|
MAE
|
RMSE
|
|
SARIMA
|
1.912
|
3.22
|
|
MLP
|
1.660
|
3.293
|
|
LSTM
|
1.566
|
3.304
|
Fonte: Os autores.
Quando
comparadas com os resultados do modelo de predição linear clássico (ARIMA), as redes
neurais artificiais obtiveram resultados melhores de MAE e de grandeza
similares no RMSE. Portanto, a partir das métricas utilizadas, observa-se o bom
comportamento das redes neurais como ferramentas para predição
5 CONSIDERÇÕES FINAIS
Assim, por meio deste trabalho foi
proposto uma metodologia de previsão de produção de energia em usinas
fotovoltaicas, utilizando dados de séries temporais, com o auxílio de algumas
ferramentas que estão à disposição do meio acadêmico e do setor energético
brasileiro, com destaque a utilização das técnicas de Machine Learning.
Para novos estudos, fica recomendado a
utilização de outros modelos, como o de Rede Neural Convolucional (CNN),
realizando uma convolução 1D (Conv1D).
Ainda, para futuros estudos, poderá
ser trabalhado o conjunto de dados do INMET de outras estações meteorológicas,
utilizando a metodologia do presente estudo, na busca de novas localidades com
alto potencial de geração fotovoltaico e com baixa potência instalada.
REFERÊNCIAS
[1] GORE, Al. Uma Verdade Inconveniente. 1. ed. São Paulo:
Manole, 2006. LAKATOS, E. M., MARCONI, M. A. Fundamentos de Metodologia
Científica. 6. ed. São Paulo: Atlas, P.10, 2005.
[2] GOLDEMBERG, J.; VILLANUEVA, L. P. Energia, Meio Ambiente &
Desenvolvimento. São Paulo: Edusp, 2003, p. 44.
[3] Emissões globais de CO2 do setor energético se estabilizaram em
2019. Época Negócios, 12 de fev. de 2020.
[4] EVOLUÇÃO DA CAPACIDADE INSTALADA NO SIN. Disponível
em: <http://www.ons.org.br/paginas/sobre-o-sin/o-sistema-em-numeros>.
Acesso em 04 de maio de 2021.
[5] PIMENTA, F. M.; ASSIREU, A. T. Simulating reservoir storage for
a wind-hydro hydrid system. Universidade Federal de Santa Catarina, 2014.
[6] A Expansão das Usinas a Fio d’Água e o Declínio da Capacidade de
Regularização do Sistema Elétrico Brasileiro. Federação de Indústrias do
Estado do Rio de Janeiro. Agosto de 2013.
[7] PERON, A. M. Análise da complementaridade das gerações
intermitentes no planejamento da operação eletro- energética da região nordeste
brasileira. UNIVERSIDADE ESTADUAL DE CAMPINAS, 2017.
[8] ALVAREZ, F. S. Desenvolvimento de um sistema computacional para
gerenciamento e análise de dados eólicos. Universidade Federal de
Pernambuco – UFPE, 2013.
[9] RENEWABLES 2020 GLOBAL STATUS REPORT. Disponível em: <https://www.ren21.net/wp-content/uploads/2019/05/gsr_2020_full_report_en.pdf>.
Acesso em 20 de maio de 2021.
[10] Pereira, E. B. et al. Atlas brasileiro de energia solar. 2.ed.
São José dos Campos: INPE, 2017. p.12.
[11] Dados da geração solar fotovoltaica no SIN. Disponível
em: <http://www.ons.org.br/Paginas/resultados-da-operacao/boletim-geracao-solar.aspx>.
Acesso em 04 de maio de 2021.
[12] Matriz Elétrica Brasileira – Filtro por fonte: UFV (Usinas
Fotovoltaicas) em operação. Disponível em: <https://bit.ly/3kLWhpg>.
Acesso em 04 de maio de 2021.
[13] MUELLER, R. W. et al. The
CM-SAF operational scheme for the satellite based retrieval of solar surface
irradiance - A LUT based eigenvector hybrid approach. Remote Sensing of
Environment, v. 113, n. 5, p. 1012-1024, 2009.
[14] HABTE, A.; SENGUPTA, M.; LOPEZ,
A. Evaluation of the national solar radiation database (NSRDB):
1998-2015. National Renewable Energy Lab. (NREL), Golden, CO (United
States), 2017.
[15] CHIN, V. J.; SALAM, Z.; ISHAQUE, K. Cell modelling
and model parameters estimation techniques for photovoltaic simulator
application: A review. Applied Energy, v. 154, p. 500-519, 2015.
[16] DE AZEVEDO DIAS, C. L. et al. Performance
estimation of photovoltaic technologies in Brazil. Renewable Energy,
v. 114, p. 367-375, 2017.
[17] HAYKIN, S. Neural Networks and Learning
Machines. Pearson Education, 3 ed., 2008, Cap.4.
[18] PALIWAL, M.; KUMAR, U. A. Neural networks and statistical
techniques: A review of applications. Expert Systems with Applications,
v.36. 2009.
[19] BROWNLEE, J. Deep learning for time
series forecasting: predict the future with MLPs, CNNs and LSTMs in python.
2019.
[20] ONS – GERAÇÃO DE ENERGIA. Disponível em: <http://www.ons.org.br/Paginas/resultados-da-operacao/historico-da-operacao/geracao_energia.aspx>.
Acesso em 11 de maio de 2021.
[21] SOLCAST, 2021. Solcast. Disponível em: <https://solcast.com/>.
Acesso em 11 de maio de 2021.
[22] CARRASCO, J. L. G; ROMANEL, C. Monitoramento da instrumentação
da barragem Corumbá I por redes neurais e modelos de Box & Jenkins. Rio
de Janeiro, 2003. 146p. Dissertação de Mestrado – Departamento de Engenharia
Civil, Pontifícia Universidade Católica do Rio de Janeiro, Capítulo 4.
[23] BROWNLEE, J. Long short-term memory
networks with python: develop deep learning models for your sequence prediction
problems. 2019.