1.
Introdução
1.1
Contextualização
Processos de
Manufatura Avançada (P.M.A.) necessitam de rigoroso controle da cadeia
produtiva e da qualidade dos itens a serem fabricados [1]. Ferramentas de gestão de processos
foram concebidas para auxiliar na análise de problemas, bem como na busca de
possíveis causa-raízes e motivos que levaram a ocorrência de falha na cadeia de
produção
[2], [3].
Com o advento
da Manufatura 4.0, sistemas informatizados que atuam em tempo real com o
processo de produção, chamados de Manufacturing Execution System (M.E.S.,
ou Sistema de Execução da Manufatura, tradução-livre do inglês) surgiram, a fim
de garantir o supervisão do fluxo fabril através de sistemas computacionais [1]–[4].
Sendo assim,
ao longo do processo de manufatura automotiva, surgem uma grande quantidade de
dados e registros das operações, peças e consumo de itens utilizados no
processo de fabricação, recursos esses que se tratados de maneira adequada e
disponibilizados para tomada de decisão do gestor do processo, podem facilitar
qual estratégia de negócio e de produção deve ser tomada [4]–[8].
As ferramentas
de gestão de processo possuem certas limitações com relação a análise de grande
volume de dados, o que torna as tomadas de decisão restritas à análises de
maneira empírica, dado experiências pontuais com os problemas e falhas que
ocorrem na cadeia de produção, onde pode se considerar ou não a repetibilidade
das ocorrências [9].
Em contrapartida, um aspecto positivo da utilização de sistemas integrados da
Manufatura 4.0 é a possibilidade da coleta dessa informação, pois ela gera
padrões que podem ser encontrados, analisados e assim serem tratados de certa
forma com técnicas computacionais que tem por base a mineração dos dados [2], [4], [5], [7], [10].
1.2
Descrição
do problema
Interrupções
em processos de manufatura ocorrem por diversos motivos, e cada um possui o que
é chamado de modo de falha [2], ou seja, como a falha veio a ocorrer. Em uma linha de
produção contínua, esses modos de falha são motivo para registro de paradas de
linha, e assim perda financeira.
Em uma linha
de produção de uma indústria do setor automotivo, o processo contínuo de
fabricação de veículos automotores pode sofrer de paradas de linha por registro
dos colaboradores de cada estação de trabalho, por parada de ferramenta, por
falta de qualidade das peças, por falta de entrega de peças no tempo correto [8].
Registros são
coletados do tempo inicial, final, de qual tipo de parada são coletados, porém
quando aplicadas as ferramentas de gestão de processos, muitas delas ficam
restritas a análises pontuais do problema, onde se considera ou não sua
recorrência, o que depende de cada caso.
1.3
Objetivos
1.3.1
Objetivo
Geral
Previsão do
perfil e do tipo de parada de linha (quanto tempo durarão as paradas de linha
no instante em que são geradas, se causada por operador ou máquina), dada
entrada de um evento de parada de linha que ocorre em tempo real.
1.3.2
Objetivos
Específicos
·
Tendência de
parada de linha de acordo com as operações executadas nas estações de trabalho
dos colaboradores;
·
Projeção das
possíveis paradas de linha que possam impactar, com maior ou menor tempo,
futuras ocorrências;
·
Modelo de previsão
retornar valores com a maior precisão possível de estimativa de tempo para
longas paradas de linha, pois assim será possível mobilizar o gestor do negócio
e o gestor da manutenção nas melhores estratégias para retorno das condições de
base da linha de produção.
1.4
Justificativa
A linha de
produção da indústria a ser analisada possui capacidade produtiva de 1.040
carros/dia sendo que, por conta de paradas de linha, a mesma atinge 920
carros/dia de produção real. É de interesse do operador do negócio o estudo,
dos últimos 3 anos (de 2018 até 2020), de todas as paradas de linha, a fim de
que se encontre oportunidades de ganho de produção e tempo na execução das
operações em todo o processo, bem como reduzir o tempo ocioso de parada de
linha, ou seja, procurar entender os modo de falha, para reduzir sua
ocorrência.
2
Fundamentação
Teórica
Para abordagem
das informações que são geradas a todo momento no ambiente industrial, a
metodologia CRISP-DM, que é a abreviação de Cross Industry Standard
Process for Data Mining que, trazendo para o português, pode ser entendida
como processo padrão da indústria cruzada para mineração de dados, foi
elaborada. Essa é uma metodologia capaz de transformar os dados da empresa em
conhecimento e informações de gerenciamento.
Criada na década de 1990, a CRISP-DM surgiu da necessidade
dos profissionais de Data Mining de padronização do processo de análise e
mineração de grande quantidade de dados. O CRISP-DM surgiu justamente para
atender aos projetos que estão diretamente envolvidos com o processamento e a
análise de um grande volume de dados. [11]
O DM faz parte
de Data Science, que utiliza estatística e matemática como base para
cruzamento de dados, por meio de técnicas de indução para propor hipóteses e
solucionar questões empresariais. De maneira simplificada, é a mineração de
dados que vai conseguir transformar todo o volume de dados em informações úteis
para o gerenciamento e a tomada de decisões.
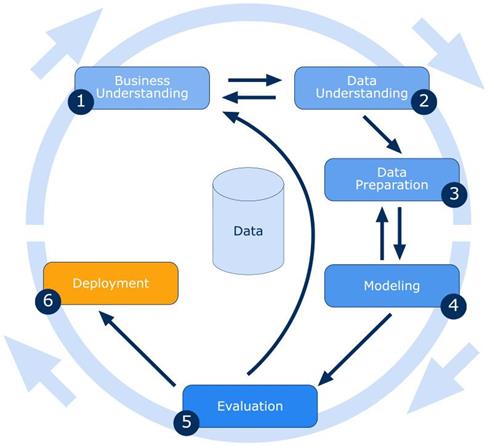
Figura
1: Ciclo de gerenciamento e implementação do CRISP-DM, e suas 6 etapas de implementação.
Fonte: https://semantix.com.br/como-explorar-e-gerenciar-dados-com-o-crisp-dm/
2.1
Área
do Negócio
A busca por
competitividade entre grandes marcas no mercado, bem como a constante melhoria
dos processos de fabricação, faz com que novos modelos e estruturas de
organização da manufatura venham a surgir como resultado final desses fatores
citados. Modelos de produção em grande escala, com definições de tarefas a
serem executadas por mão-de-obra, seja ela qualificada ou não, foram
conceituados nas revoluções industriais ocorridas nos séculos XIX e XX [12].
Dos modelos de
organização industrial existentes, três exemplos se destacam, dos quais:
Taylorismo, Fordismo e Toyotismo. Do primeiro citado, o Taylorismo, temos a
criação do conceito de Administração Científica de um processo de produção [12], que se caracteriza por:
·
Priorização do
métodos científicos, em face dos empíricos;
·
Recrutamento do
melhor colaborador para cada parte do processo de manufatura;
·
Capacitação
constante do colaborador;
·
Cooperação entre
líderes e liderados;
·
Estudos de tempos
e movimentos dos colaboradores.
Seguindo as
definições, o Fordismo foi conceituado por Henry Ford como uma adaptação do
Taylorismo: com a adição de um processo contínuo e ininterrupto, a exemplo uma
“esteira rolante”, ditando assim um novo ritmo de trabalho. Com isso, Henry
Ford conseguiu reduzir ainda mais o tempo no processo de manufatura, além de
permitir a introdução de maquinário trabalhando em conjunto com seres humanos,
como também fazendo com que fornecedores de peças e itens a serem montados no
produto ficassem localizados cada vez mais próximos do processo de montagem
final [12].
Com a mudança
no perfil de consumo das pessoas nos séculos XX e XXI, um sistema surgido no
Japão pós-segunda guerra mundial, chamado Toyotismo, emergiu com o conceito de
fabricação simples e enxuta [12]. Nesse modelo de produção, os lotes de produção são baseados na demanda
dos clientes, não possuindo assim estoque como no Taylorismo e Fordismo, o que
já evita desperdício de materiais e mão-de-obra. Além disso, o colaborador
executa várias tarefas em escala (multitarefas) e existe uma integração maior
com o espaço de trabalho.
Para o setor
automotivo, o modelo Toyotista ganhou cada vez mais espaço, também com o
advento da manufatura enxuta [13], que pelo seu conceito visa cada vez mais a melhoria do processo com o
controle e diminuição dos custos e tempo de produção, mantendo a qualidade de
todo o processo, em conjunto com a manufatura 4.0, recebendo esse nome por ser
contemporânea a 4ª revolução industrial – uso de tecnologias de ponta e
processos computacionais [2], [14]. Sendo assim, possui como meta a
integração dos processos de manufatura a sistemas computacionais de controle de
produção, qualidade e tempo de operação na linha contínua. Adicionalmente, o
conceito de Manufatura de Classe Mundial (do inglês World Class
Manufacturing – W.C.M.) surge já na década de 1980 para integrar as
diversas definições de melhoria de processo de produção da manufatura, visando
sempre o controle do tempo de execução, qualidade, segurança do colaborador e
entrega eficaz e efetiva do produto final para o cliente [14].
Portanto, a
proposta de melhoria de processo por paradas de linha de produção, bem como a
diminuição desse tempo à luz do que ocorre em toda a cadeia de produção de uma
empresa do setor automotivo, permite a implementação da mineração dos dados
coletados pelos sistemas de controle do processo de manufatura, a fim de que
sejam encontrados padrões de perdas produtivas, com proposta através da análise
realizada de diminuir os impactos na produção, em conjunto com o uso de
ferramentas empíricas de gestão de processos, como o W.C.M.
2.2
Mineração
de Dados
Mineração de
Dados (Data Mining, em tradução livre) é o nome dado a um conjunto de técnicas
e procedimentos que tenta extrair informações de nível semântico mais alto a
partir de dados brutos, em outras palavras, permitindo a análise de grandes
volumes de dados para extração de conhecimento [1], [3].
Este
conhecimento pode ser na forma de regras descritivas dos dados, modelos que
permitem a classificação de dados desconhecidos a partir de análise de dados já
conhecidos, previsões, detecção de anomalias, visualização anotada ou dirigida,
entre outros. Embora muitas destas abordagens tratem com dados tabulares, é
possível extrair informações tabulares de dados estruturados de forma
diferente, como na Web. [11].
Para
identificarmos quando uma base de dados é adequada para uma mineração de dados
ou não, o conjunto de dados deve representar, de forma confiável, o universo
(mundo real) a ser investigado, possibilitando assim inferir a situação
problema como um todo, seja pela perspectiva de completeza ou complexidade do
problema. Um dos “mitos” criados, a partir da motivação inicial das discussões
sobre a mineração de dados, era ser uma alternativa para “grandes” bases de
dados [4], [9].
Este fato
decorreu da própria dificuldade de processamento inerente à descoberta e
identificação de informações oportunas ao processo decisório em grandes
conjuntos.
Como muitas
bases de dados sofrem interferências de diversas formas, a elas atribuimos o
nome de ruído. “Ruído” representa conteúdo nas bases de dados que pode
prejudicar a qualidade da informação extraída, a partir de qualquer método,
seja ele tradicional ou baseado em estratégias mais elaboradas. Destacam-se
como ruídos: valores fora do domínio, ausência de valores, inconsistências,
dentre outras [9], [11].
É importante
lembrar que o mundo real é ruidoso, ou seja, se uma base de dados representa
uma abstração deste mundo real, esta será ruidosa a despeito dos esforços
despendidos para a sua modelagem e respectiva população. Cabe aos profissionais
da área de tecnologia da informação minimizar o impacto negativo que estes
ruídos possam representar nas informações extraídas e disponibilizadas aos
gestores. Por exemplo, todas as vezes que, ao informar os dados cadastrais se omite
ou não se informa corretamente a renda, gera-se um ruído no conjunto de dados [11].
2.3
Trabalhos
Relacionados
Processos de
Manufatura Inteligente demandam aplicações de alta complexidade, no que se
refere a estudos de caso que indiquem soluções para, por exemplo, problemas de
falta de qualidade no item manufaturado, ou até mesmo paradas de produção
provocadas por falha em equipamentos. A integração de sistemas de automação
com soluções de Internet das Coisas (do inglês Internet of Things, com
sigla IoT) permite a aquisição de grande volume de informações, o que
muitas vezes deixam de ser analisados por falta de conhecimento para tal [15]. Para esses e outros casos ligados a
otimização da produtividade em indústria e processos de manufatura, a mineração
de dados surgiu com o propósito de extração de informações, que eram
desconhecidas até então, e assim torná-las válidas, bem como compreensíveis, de
grandes bases de dados com o intuito de melhorar e otimizar as tomadas de
decisão que devem ser feitas pelo gerente do negócio [9].
Técnicas
diversas para extração de informação de grande quantidade de dados, tais como Random
Forest, redes Bayseanas, algoritmos de classificação, redes neurais
artificiais (da sigla RNA), árvores de decisão, sistemas de lógica Fuzzy
e algoritmos genéticos, são utilizadas como propostas de solução, dependendo do
cenário que exige solução de problema proposto [4], [6]–[8], [16].
Em se tratando
da abordagem Random Forest, este método consiste nas correlações que são
estimadas de acordo com os resultados de saída de várias árvores de decisão,
onde esses diversos resultados das saídas são combinados, para assim termos uma
saída única. Cada resultado de saída corresponde a uma “escolha” que é feita
pela árvore de decisão, em sua unidade, sendo que cada árvore trabalha com um
trecho de amostras da base de dados, onde esses trechos são aleatórios e de
mesmo tamanho, para que não haja desbalanceamento das sub-bases. A combinação
de todas as escolhas denota na escolha global, onde cada árvore de decisão que
participa do processo possui igual poder de decisão no valor de saída final,
sendo esse do Random Forest, correspondente então a base de dados
completa [17].
Aplicações do
Random Forest para detecção de defeitos em soldas feitas por robô [17], bem como detecção de falhas em
camadas de dispositivos semicondutores em sua fase de fabricação [16] são exemplos de situações onde o Random
Forest foi aplicado para previsão de situações que estavam fora do padrão
esperado, para controle do processo de manufatura avançada e de qualidade
exigido em cada cenário citado.
3
Materiais
e Métodos
3.1
Descrição
da base de dados
A Base de
dados analisada possui, em tamanho total, 1.2GB de informações, contendo na
mesma 12 colunas com 579.237 linhas de informações acerca dos mais variados
tipos de operações que resultaram em paradas de linha. Foram levantados dados
de 2018 até 2020 de histórico de paradas de linha, com extração realizada em um
banco de dados SQL. A Tabela 1 mostra dicionário de dados montado.
Tabela
1: Dicionário
de dados utilizado para previsão
|
Nome do campo
|
Tipo de dado
|
Descrição
|
|
ProductionOrderId
|
Long
|
Número de batismo do veículo.
|
|
CallStartTime
|
Time
|
Tempo que marca o início do alerta de da parada de linha.
|
|
CallEndTime
|
Time
|
Tempo que marca o fim de parada de linha.
|
|
Time_DIFF
|
Time
|
Diferença de tempo entre CallEndTime - CallStartTime
|
|
StopLineStartTime
|
Time
|
Tempo que marca o início de parada de linha.
|
|
StopLineEndTime
|
Time
|
Tempo que marca o fim de parada de linha.
|
|
StopButtonStartTime
|
Time
|
Tempo que marca o início da solicitação de parada de linha
|
|
StopButtonEndTime
|
Time
|
Tempo que marca o fim da solicitação de parada de linha
|
|
Workplace
|
String
|
Código referente a estação de trabalho onde houve parada de linha.
|
|
Type
|
String
|
Tipo de parada: se causada pelo operador, se a parada da linha foi
causada por falha na máquina.
|
|
Type_BIN
|
Long
|
0 = Operator; 1 = Fail
|
|
Operation
|
String
|
Tipo de operação que houve parada.
|
3.2
Análise
Descritiva dos Dados
Temos, de
parte dos atributos numéricos, os tipos de dados sinalizados como Time,
que correspondem a todos os tempos de início e fim de parada de linha na
produção. Já os que estão indicados como sendo de atributo nominal, que são do
tipo String, representam o local onde houve a parada de linha, o modo de
parada – se parada executada por ação humana, ou máquina – e qual tipo de
operação foi impactada com a parada de linha.
Em relação a
este último – nome do campo Operation – temos a classificação em: parada
por conta de ferramentas (índice SCR, GEN, F), paradas por falta de qualidade
na operação (tipos QCE), parada por falta de finalização do processo (tipos
PCE) e paradas por falta de leitura de peças montadas (TRA, TRP, OGG, CERT,
CEL). O tipo de dado que ficou sinalizado como Long representa o número
de batismo da carroceria, o mesmo que vai na documentação do carro e fica
atrelado ao chassi do mesmo. Toda vez que existe uma parada de linha na
produção, o valor de início, fim, qual estação de trabalho e qual operação
sofreu impacto é registrado no sistema de manufatura.
Através da
tabela de informações sobre as paradas de linha, foram escolhidos como
atributos numéricos a diferença de tempo entre o início e fim da parada
(chamado de CallStartTime e CalllEndTime, respectivamente) e como
atributo de classe se a parada de linha foi gerada por operador (nomeada de Operator),
ou por falha no processo (Nomeada de Fail).
Extrações de
gráficos também foram realizadas, de tal forma que foram expostos na primeira
análise de tempo, todos os valores de tempo encontrados, em segundos, conforme Figura
1.
Diante de
melhor análise a se tornar evidente, foi realizada nova extração mostrada na Figura
2, essa com os primeiros 1000 segundos de paradas, pois foi percebido que as
paradas de linha estavam mais concentradas nesse intervalo de tempo.
Logo em
seguida, para refinamento ainda mais detalhado da informação, foram
evidenciados os 50 primeiros valores medidos de tempo, também em segundos, da
quantidade de ocorrências de parada de linha de produção (ou seja, quantas
vezes uma parada de 1 segundo influenciou no total de paradas), exibidos na Figura
3.
3.3
Pré-processamento
dos dados
Por critério
de seleção, foram escolhidas as colunas CallStartTime e CallEndTime
para análise a diferença de tempo de parada de linha na produção, e assim
criada uma nova coluna chamada Time_Diff. Também foi realizada a criação
de uma coluna intitulada Type_BIN, que corresponde a informação binária
da coluna Type, onde o índice 0 corresponde a todas as paradas relacionadas a operator
e o índice 1 a todas as paradas relacionadas a fail das operações,
constando sempre o tipo de operação que provocou a parada, na coluna Operation.
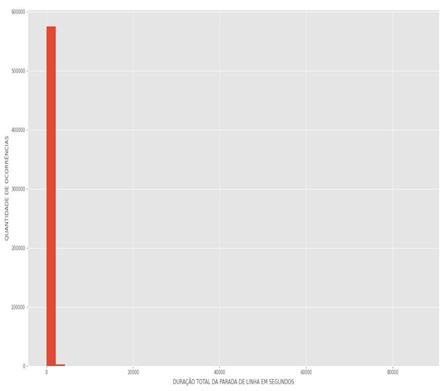
Figura 2: Análise do total de ocorrências de
paradas de linha, em segundos.
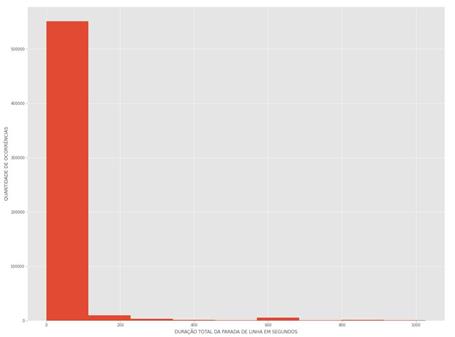
Figura 3: Análise dos primeiros 1000 segundos
de parada de linha.
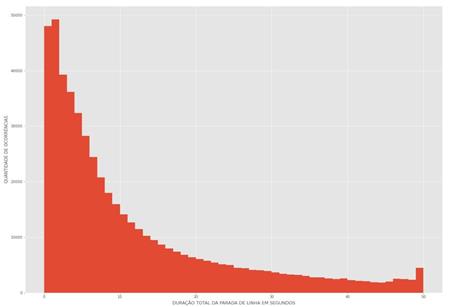
Figura 4: Análise dos 50 primeiros valores de
tempo, em segundos, correspondente as ocorrências de paradas de linha.
Para também
melhorar a execução de nosso algoritmo, como também termos uma categorização
das classes de maneira mais adequada, foram criadas novas colunas, em formato
de labels, das colunas trabalhadas nesta base de dados, dos quais:
·
Workplace_Category:
label encoder de workplace;
·
Operation_Category:
label encoder de operation;
·
Criação de
StopLineShift (período do dia da parada): com label enconder, categorizada para
StopLineShift_Category, se no primeiro, segundo ou terceiro turno de produção;
·
Criação de
StopLineCriticality (criticidade da parada): com label encoder, categorizada
para StopLineCriticality_Category, criticidade da parada de linha;
·
Chassis_Category -
label enconder de ProductionOrderId.
Também
foram necessárias algumas transformações de colunas e variáveis, para correto
ajuste da base de dados disponibilizada ao modelo de previsão, que foram as
seguintes:
·
TimeDiffSeconds:
transformação de TIME_DIFF em segundos;
·
Criação da coluna
Time_diff_seconds_bins: distribuição da classe TimeDiffSeconds em ranges de
tempo, para melhor análise da abordagem de Random Forest na base de
dados;
·
Colunas da base de
dados utilizadas para treinamento do modelo: ["Chassis_Category",
"Type_BIN", "Workplace_Category",
"Operation_Category", "Time_diff_seconds_bins",
"StopLineShift_Category", "StopLineCriticality_Category"]
Finalmente,
temos a organização tanto da base de dados, como dos gráficos gerados e do
treinamento e validação do modelo no formato de arquivos de processamento,
debug e geração de dados no formato de plataforma colaborativa, como exemplo a
que foi utilizada, o Google Colab. Na plataforma em questão, foram
elencados coluna para as seguintes distribuições:
·
Turno de
ocorrência da parada de linha, se primeiro, segundo ou terceiro turno de
produção;
·
Criticidade da
parada de linha, de acordo com a quantidade, em segundos da parada de linha. Os
indicadores para criação dessa nova coluna foram sinalizados como:
o Se tempo de parada entre 0 e 540
segundos, criticidade baixa;
o Se tempo de parada entre 541 e 1140
segundos, criticidade média;
o Se tempo de parada entre 1141 e 1740
segundos, criticidade alta;
o Se tempo de parada entre 1741 e 2340
segundos, criticidade altíssima;
o Se tempo de parada maior que 2341
segundos, criticidade desastre.
3.4
Metodologia
Experimental
Primeiramente,
a coleta de informações foi realizada através de um arquivo .csv disponibilizado
pelo stakeholder, para fins de análise e tratamento das linhas, quando
necessário, com características já citadas em 3.1. Logo após, foram definidas
quais transformações seriam necessárias para adaptação da base de dados, e
assim ter a possibilidade de manipulação o mais adequada possível dos dados,
tanto para a aquisição de gráficos relativos a paradas de linha de produção, e
sua quantidade de paradas de acordo com a estação de trabalho, por exemplo,
como para o modelo de previsão proposto, para nosso cenário o Random Forest,
conforme mencionado em 3.3.
Em seguida,
foi realizado o processamento da base, de acordo com os atributos de classe
escolhidos e assim categorizados, para melhor análise e performance do modelo
utilizado. Com isso, foi possível a extração total da quantidade de paradas de
linha existentes, do tempo que cada uma dessas paradas de linha influenciou na
linha de produção, a tendência de maior ocorrência de paradas de linha, por
exemplo, se quando com tempo menor que 60 segundos ou maior que 60
segundos.
Finalmente, já
para o modelo de previsão utilizado, as colunas criadas em 3.3 suportaram a
estimativa dos valores encontrados, tanto para a parte da base de dados que foi
utilizada para treinamento do modelo, como para validação do mesmo. Foi feita
uma distribuição de classes, onde os períodos de tempo que houveram maiores
ocorrências de parada de linha recebem o menor intervalo de classes, para assim
a previsão ocorrer o mais próxima do esperado, em se tratando da realidade de
paradas de linha da produção, e um balanceamento da quantidade de amostras de
cada classe, de tal forma que para a base de treinamento ter a mesma quantidade
de amostras da classe com menor quantidade de amostras, que no caso foi a
classe 10 com 2410 amostras, independente do intervalo de classes, fazer o
treinamento da previsão o mais balanceado possível.
Adicionalmente,
das classes com mais amostras foi realizado uma permuta de índices, para
validação do treinamento. Com o proposto, conseguimos uma estratificação de 12
intervalos de classe, que nos permite assim identificar melhor os padrões de
criticidade de parada de linha. Os intervalos das classes estão apresentados na
Figura 5:
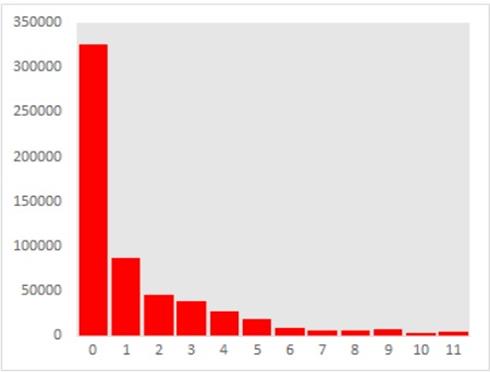
Figura 5: Gráfico contendo a estratificação da quantidade de
amostras, de acordo com as classes separadas para previsão das paradas de
linha.
4
Resultados
Antes do
balanceamento das amostras nas classes ser realizado, conforme comentado em
3.4, o modelo de previsão fez o processamento das informações contidas na base
de dados, de acordo com a quantidade de amostras presentes em cada intervalo de
classes, desconsiderando assim o mínimo valor de amostras apontado na classe 10
utilizado para, posteriormente, balancear a quantidade de amostras nas demais
classes, de 2410 registros. Eis que os resultados obtidos pela precisão do
modelo Random Forest seguem abaixo:
Tabela 2: Valores
de acurácia do modelo de previsão, sem o balanceamento da quantidade de
amostras entre as classes.
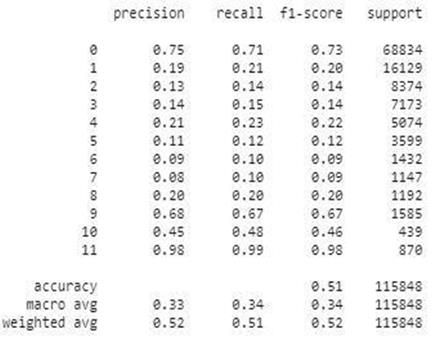
Com a acurácia
em 51%, foi necessário reanalisar o pré-processamento, para entendimento dos
valores, e foi constatado que seria necessário uma nova distribuição de
amostras entre as classes era necessária para uma nova validação do modelo de
previsão, mantendo como meta os intervalos de tempo que possuem maiores
ocorrências de parada de linha, como o menor intervalo intra-classe.
Sendo assim, a
validação do modelo fica mais detalhada, de tal forma a saber se várias paradas
de criticidade baixa influenciam com maior ou menor frequência do que uma
parada longa que causa um valor alto de parada de linha de produção. Depois do
balanceamento das classes, temos o seguinte resultado para a previsão:
Tabela 3: Valores de acurácia do modelo de
previsão, com o balanceamento da quantidade de amostras entre as classes,
baseado na classe com menor quantidade de índices, no caso a classe 11, com 2410
registros.
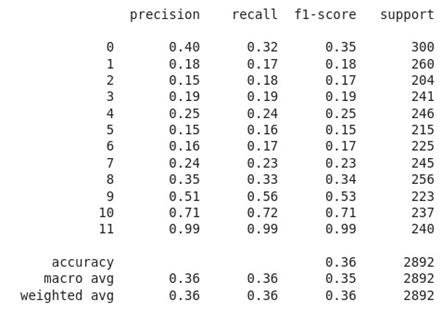
Tabela 4: Valores de acurácia do modelo de
previsão, com o balanceamento da quantidade de amostras entre as classes,
baseado na classe com menor quantidade de índices, no caso a classe 11, com
2410 registros, variando em termos de amostras, conforme as já utilizadas em
primeira validação do modelo.
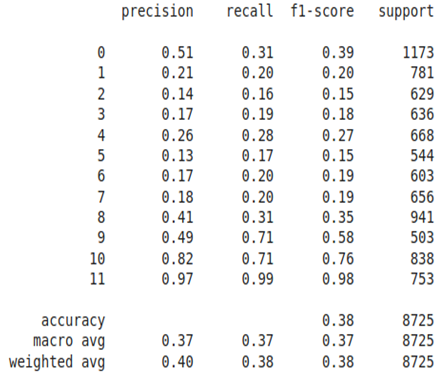
A avaliação
que é feita também para treinamento do modelo, considerou a substituição de
valores onde tivemos classes com mais do que 2410 registros, e não houve
mudança brusca nos valores de precisão atingidos, conforme tabelas 5 e 6 acima,
que registraram 36% e 38% de previsão final, respectivamente. Houve
considerável melhora nas previsões das classes 5 até a 11, que para o gerente
do negócio torna-se mais interessante saber, por exemplo, com mais precisão
quando paradas registradas na base de dados que são acima de 1 minuto podem impactar
o processo de produção.
Em se tratando
das paradas com menos de 1 minuto, por mais que ocorram com maior frequência, é
de se saber que são paradas que ocorrem, pelo presente estudo, por falta de
adequação do tempo-ciclo de operação dos colaboradores nas estações de
trabalho.
4.1
Discussão
Com os
resultados encontrados, o gerente do negócio da indústria estudada pode, então,
ter tomadas de decisão de tal forma que as paradas de linha que mais impactam o
processo são aquelas em que:
·
O templo-ciclo de
execução da operação não está conforme o previsto para o ritmo da linha de
produção, ou seja, curto espaço de tempo para várias atividades na estação de
trabalho serem exercidas;
·
Falta ou
reciclagem de treinamento e capacitação do colaborador em realizar as
atividades, de acordo com a estação de trabalho;
·
O número de carros
por hora que são fabricados na linha não está de acordo com a quantidade de
colaboradores exigidos para execução da quantidade de atividades nas estações
de trabalho;
·
Quebras
ocasionadas por ferramentas do processo precisam de maior monitoramento do time
da Manutenção, com relação a ações de execução das atividades necessárias de manutenção
preventiva/preditiva.
5
Conclusões
e Trabalhos Futuros
O
perfil de perda a ser previsto auxiliará na tomada de decisão do gerente do
negócio quando, por exemplo, eventos de paradas de programação para reparação
dos equipamentos serão necessários de acontecer, para prevenir grandes paradas
de linha.
É
esperado, também, com os valores encontrados pela previsão, aumento na
eficiência e eficácia em cada estação de trabalho, considerando que correções
no tempo-ciclo de operação já citados sejam realizados, para assim atingir o
objetivo da previsão mais próxima da realidade de modos de falha para as
paradas de linha que ocorrem na manufatura.
Como
proposta de trabalho futuro, a correlação dessa base de dados com outras bases
de dados que coletam informações distintas de perdas produtivas, como perdas
por atraso logístico externa a cadeia de produção, perdas por falha de outras
oficinas ligadas a entrega de peças e carrocerias para manufatura, a saber da
oficina de Prensas de chapas e do parque de fornecedores.
Finalmente,
também segue a proposta da aplicação de outras técnicas de previsão, a saber
séries temporais, algoritmos genéticos, e quaisquer outras técnicas de
algoritmos de aprendizado de máquina ou de inteligência artificial, que possa
retornar valores adequados para auxílio do gerente do negócio na tomada de
decisão.
Referências
[1] M. G. B, S. Chren,
B. Rossi, and T. Pitner, for Smart Grid Systems, vol. 1. Springer
International Publishing, 2019.
[2] M. Syafrudin, G.
Alfian, N. L. Fitriyani, and J. Rhee, “Performance analysis of IoT-based
sensor, big data processing, and machine learning model for real-time
monitoring system in automotive manufacturing,” Sensors (Switzerland),
vol. 18, no. 9, 2018.
[3] L. Rokach and O.
Maimon, “Data mining for improving the quality of manufacturing: A feature set
decomposition approach,” J. Intell. Manuf., vol. 17, no. 3, pp. 285–299,
2006.
[4] C. Gröger, F.
Niedermann, and B. Mitschang, “Data mining-driven manufacturing process
optimization,” Lect. Notes Eng. Comput. Sci., vol. 3, pp. 1475–1481,
2012.
[5] G. Filios, “An
Agnostic Data-Driven Approach to Predict Stoppages of Industrial Packing
Machine in Near Future,” pp. 236–243, 2020.
[6] C. Dudas, M.
Frantzén, and A. H. C. Ng, “A synergy of multi-objective optimization and data
mining for the analysis of a flexible flow shop,” Robot. Comput. Integr.
Manuf., vol. 27, no. 4, pp. 687–695, 2011.
[7] C. Dudas, A. H. C.
Ng, L. Pehrsson, and H. Boström, “Integration of data mining and
multi-objective optimisation for decision support in production systems
development,” Int. J. Comput. Integr. Manuf., vol. 27, no. 9, pp.
824–839, 2014.
[8] A. Luckow et al.,
“Artificial Intelligence and Deep Learning Applications for Automotive
Manufacturing,” Proc. - 2018 IEEE Int. Conf. Big Data, Big Data 2018, pp. 3144–3152, 2019.
[9] K. Wang, “Applying
data mining to manufacturing: The nature and implications,” J. Intell.
Manuf., vol. 18, no. 4, pp. 487–495, 2007.
[10] A. Majeed, J. Lv, and
T. Peng, “A framework for big data driven process analysis and optimization for
additive manufacturing,” Rapid Prototyp. J., vol. 25, no. 2, pp.
308–321, 2019.
[11] P. C. Ncr et al.,
“Step-by-step data mining guide,” SPSS inc, vol. 78, pp. 1–78, 2000.
[12] C. J. Muller, “A evolução dos sistemas
de manufatura e a necessidade de mudança nos sistemas de controle e custeio,”
p. 222, 1996.
[13] L. C. Maia, a. C. Alves, and C. L. Leão,
“Metodologias Para Implementar Lean Production: Uma Revisão Critica De
Literatura,” ClLME´2011, p. 0915A, 2011.
[14] F. Pereira, L. Carelli, C. Manuel, T. Rodriguez,
and L. M. Rôa, “Proposta de adequação do processo de inspeção com base nos
conceitos do lean manufacturing : estudo de caso em um fabricante de
equipamentos agrícolas.,” vol. 1, p. 86, 2016.
[15] D. Wu, C. Jennings, J.
Terpenny, R. X. Gao, and S. Kumara, “A Comparative Study on Machine Learning
Algorithms for Smart Manufacturing: Tool Wear Prediction Using Random Forests,”
J. Manuf. Sci. Eng. Trans. ASME, vol. 139, no. 7, 2017.
[16] L. Puggini, J. Doyle,
and S. McLoone, “Fault detection using random forest similarity distance,” IFAC-PapersOnLine,
vol. 28, no. 21, pp. 583–588, 2015.
[17] Z. Zhang, Z. Yang, W.
Ren, and G. Wen, “Random forest-based real-time defect detection of Al alloy in
robotic arc welding using optical spectrum,” J. Manuf. Process., vol. 42, no. April, pp.
51–59, 2019.